
Aggregating GraphQL APIs using Negron
• 7 min read • graphql nodejs microservices
Since Facebook open source GraphQL in 2015, the popularity of this specification didn’t stop growing.
This post was originally published in Spanish here.
GraphQL is just a specification of a data language and has nothing to do with the protocol where it travels, existing as an alternative not only to a RESTful design of an HTTP API but as a possible contract for internal APIs within an application or any type of third-party libraries.
In software engineering, we must take into account the tradeoffs of using one technology instead of another in order to always make the most knowledgeable decisions possible prior to implementing a solution to a problem. In this post, we will see an example where it could be reasonable to use GraphQL instead of a RESTful architecture.
Our startup
We already have a millionaire idea: Frasaza.com. It will be a MaaS (Motivation as a Service), where we’ll sell motivational quotes at a fair price.
For our MVP we’ll start with just a web application. In the future, we know our user base will grow exponentially and we’ll need native mobile apps, so we are going to design an architecture that scales properly. We are going to start building a SPA (Single Page Application) which will query an API serving motivational quotes.
REST vs GraphQL
It’s time for us to implement our API, how we build it? Within our app, quotes are composed by:
- Author, whenever known (would have an id and a name).
- Content, the motivational quote.
- Topic.
- Id.
We should be able to:
- Filter quotes by topic.
- Filter quotes by its author.
- Filter quotes by id.
In the case we design the API following a RESTful convention, we would create two endpoints:
- GET
/quotes/:id: where:idis the quote’s id. - GET
/quotes?topic=:topic&author_id=:author_id: where:topicand:author_idare optional parameters.
In addition to implementing all the error handling and validation logic for the arguments, we should consider document our API using tools as Swagger.
If we were to use GraphQL, we could define an interface with types and queries, so that our API would have the following types:
type Author {
id: UUID!
name: String!
}
enum Topic {
INSPIRATIONAL
MENTORSHIP
ENTREPRENEURSHIP
}
type Quote {
id: UUID!
author: Author
content: String!
topic: Topic!
}In GraphQL the keyword ! after a type means that the field is compulsory (as an argument or a field within an object). Not only we have simply and custom types but we also could leverage enumerations (enum) which allow us to limit the possible inputs our API accepts.
We will also have the following Query in our application:
type Query {
quotes(id: UUID, authorId: UUID, topic: Topic): [Quote]
}This query has three optional parameters and will return an array of quotes. We could query the quotes list as follows:
query {
quotes(id: $id, authorId: $authorId, topic: $topic) {
id
content
topic
author {
id
name
}
}
}Where $id, $authorId, and $topic are optional variables we could send in order to filter the results.
One of the main key points of GraphQL is the ability, without implementing anything extra at the server side, to create, from the client, queries like the following one where we are removing the content we don’t need:
query {
quotes(id: $id, authorId: $authorId, topic: $topic) {
content
}
}Given that there are plenty of libraries implementing the GraphQL specification for almost all the popular languages, we’d have all the types and error handling as well as the documentation for free, without the need of implementing it, allowing us to put more attention implementing the business logic of our application.
Deploying our MVP
The day has come! We just build our API using Ruby and our SPA using React (with Apollo as the GraphQL client implementation) and we are ready to deploy it to production. Everything looks great and our architecture is something similar to this:

We want feedback
Sells couldn’t be better, so we want to add a new feature to gather feedback about our quotes in order to know which ones are the most popular.
As we don’t want this new feature to compromise our existing service, we are going to develop a new service using Elixir and as we had a pleasant journey working with GraphQL, we are going to implement the API of this service using GraphQL too. The mutation for this service will be as follows:
type Mutation {
giveFeedback(score: Int!, comment: String): String
}We build the service and in order to integrate it with our existing frontend, we came up with an architecture like the following one:
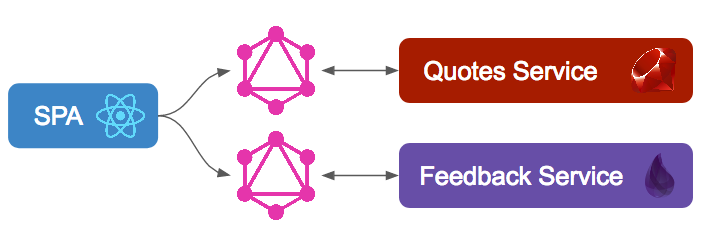
However, a single GraphQL client shouldn’t query more than one endpoint, so that architecture isn’t supported in the Apollo client. GraphQL was thought, as opposed to REST, to serve just a single endpoint to the client which will use our services.
Building Negron
At The Cocktail, we faced a similar architecture and we built a tool that allows us to aggregate several GraphQL endpoints in just one. We called this tool Negron.
With Negron, our architecture would look something like this:
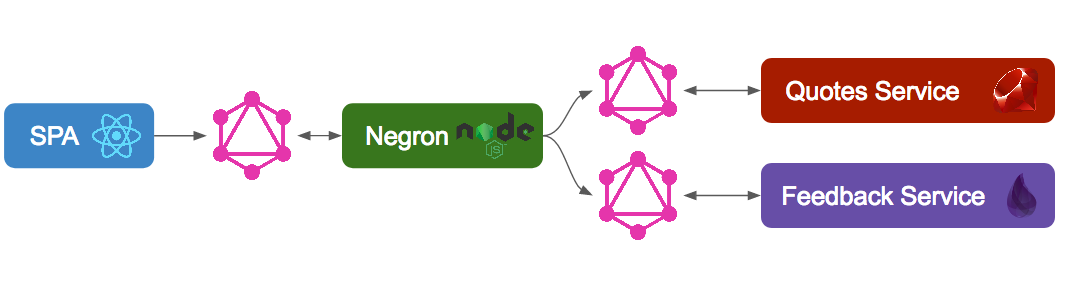
Now we’ll query just one endpoint that will be set up by Negron, unifying the APIs of all services we configure, thanks to the technique known as schema stitching.
Using Negron
Negron could be started as a Docker container, as well as a Node.js application.
If our services lived at:
https://quotes.frasaza.com/graphqlhttps://feedback.frasaza.com/graphql
We can start Negron (https://api.frasaza.com/graphql) with the following command:
docker run \
-e NEGRON_PATH=/grapqhl \
-e PROVIDER_URL_QUOTES=https://quotes.frasaza.com/graphql \
-e PROVIDER_URL_FEEDBACK=https://feedback.frasaza.com/graphql \
thecocktail/negronWith this command, we’d have our GraphQL gateway listening at port 3000 and we could send the quotes query and the giveFeedback mutation directly against https://api.frasaza.com/graphql.
Pitfalls
When using schema stitching, we are at risk of encounter type collisions between services, so it is important for the type names (fields, queries, and mutations) to not be the same. In case those collide, the last service to be aggregated will override the type.
Conclusion
Although GraphQL, and its implementations, offer a huge range of tools, it’s important to consider our architecture and our requirements before deciding if we chose GraphQL over REST, since not in every scenario GraphQL makes a difference.
On the other hand, Negron isn’t limited to aggregate internal APIs, thanks to its simple configuration, it could also be used as a proxy for external APIs in order to have better control over the API traffic.
If you like the project, have questions or suggestions, any contribution to our GitHub repository will be more than welcome.